2022. 10. 10. 17:29ㆍ카테고리 없음
히스토리
- 초안 작성
작년부터 조금씩 글을 작성해서 2023년 6월 28일 작성을 완료했다.
이렇게 굉장히 글을 오래 써본 건 처음이다.
새삼 책을 쓰시는 분들을 존경하게 됐다.
굉장히 장기적으로(예상 기간 올해 12월 31일까지) MySQL의 명령어 위주로 적으려고 합니다.
2022년 하반기에 작성한 글이었고 2023년이 왔지만 작성 중입니다.
목표는 이번 연도 2분기까지 작성을 목표로 하고 있습니다.
이 내용은 포스트가 완료되면 완료로 글 내용이 변경될 겁니다.
MySQL VERSION 5를 기준으로 적을 예정입니다.(책이 5 버전이라...ㅠ.ㅠ)
6~8 버전은 큰 문제없다면 내년 상반기 때 같이 적어서 끝날 거 같습니다.
그럼.. 시작!!

모든 명령어는 mysql 클라이언트를 사용할 때의 기준입니다.
OS는 리눅스 우분투에서 MySQL 8.0 버전을 설치 후 테스트했습니다.
- 명령어 내용의 기호 의미
- () : 필수
- [] : 선택
- 자주 사용하는 명령어는 별 표시 및 빨간색 색상 추가
- ★ : 많이 사용
- 색상
- 빨간색 : 중요
- 파란색 : 보통
- 초록색 : 가끔
핵심 내용만 알 수 있도록 적었습니다.
자세한 내용은 따로 포스트를 생성해 적을 예정입니다.
계정 생성은 SQL root 권한으로 접속해서 명령어를 실행해야 합니다.
root 권한으로 접근하는 방법은 리눅스에서 root 계정으로 접속 후 mysql을 입력하면 자동으로 접속됩니다.
- 계정 생성
- CREATE USER '(ID)'@'(IP)' IDENTIFIED BY '(PASS WORD)';
- IP 부분은 로컬에서만 접속 가능하게 하려면 localhost 입력
- 외부 접속도 가능해야 된다면 % 입력
- CREATE USER '(ID)'@'(IP)' IDENTIFIED BY '(PASS WORD)';
- 권한 생성
- GRANT ALL ON (데이터베이스 명).* TO '(ID)'@'(IP)';
- 데이터베이스 명은 접근 가능한 데이터베이스를 지정한 거고 전체 권한을 지정하고 싶다면 *만 입력하면 됩니다. 하지만 보안을 위해 각 ID마다 접근 가능한 데이터베이스 명만 권한으로 주는 게 좋습니다.
- GRANT ALL ON (데이터베이스 명).* TO '(ID)'@'(IP)';
- MySQL 접속
- 로컬 접속 일 경우
- mysql -p -u (mySQL ID) [데이터베이스 명]
- 원격 접속 일 경우
- mysql -h (호스트 주소) -p -u (mySQL ID) [데이터베이스 명]
- [데이터베이스 명]을 가치 입력할 경우 접속과 동시에 해당 데이터베이스를 선택한 상태가 됩니다
- 로컬 접속 일 경우
- 접속 후 데이터베이스 선택 ★
- USE (데이터베이스 명);
- 선택한 데이터베이스 출력 ★
- SELECT DATABASE();
- .SQL 파일을 MySQL에 적용
- mysql < (파일명).sql [-p] [-u] [mySQL ID]
- 위 명령어는 데이터베이스에서 사용하지 않은 쿼리들만 있을 경우에 가능합니다.
- 예) now(), user()..etc
- mysql (데이터베이스 명) < (파일명).sql [-p] [-u] [mySQL ID]
- mysql < (파일명).sql [-p] [-u] [mySQL ID]
- 데이터베이스 리스트 출력 ★
- SHOW DATABASES;
- 테이블 리스트 출력 ★
- SHOW TABLES;
- 테이블 내용 출력
- DESCRIBE (테이블 명);
- DESC (테이블 명);
- EXPLAIN (테이블 명);
- SHOW COLUMNS FROM (테이블 명);
- SHOW FULL COLUMNS FROM (테이블 명);
- SHOW FIELDS FROM (테이블 명);
- SHOW 구문으로 검색할 경우 LIKE 구문을 사용해서 테이블 칼럼의 부분만 출력할 수 있음
- SHOW COLUMNS FROM (테이블 명) LIKE '(%검색할 칼럼 명)';
- 칼럼들의 이름을 알 경우 칼럼 이름만 선택해서 출력할 수 있음
- DESCRIBE (테이블명) (칼럼명 1) (칼럼명 2)...;
- 데이터베이스 생성
- CREATE DATABASE (데이터베이스 명);
- 테이블 생성
CREATE TABLE (테이블 명)
(
(데이터 이름) (데이터 타입) (옵션),
(데이터 이름) (데이터 타입) (옵션)
);- 테이블에 데이터 추가
- INSERT문 ★
-- 1 기본 형식(모든 컬럼에 값을 입력할 경우)
-- 값 순서(값1, 값2)는 Table에 저장된 컬럼 순서대로 입력 해야 한다.
-- 입력한 순서는 보통 CREATE TABLE로 테이블을 생성할때 컬럼 순서이고 확인 하고 싶을 경우 DESCRIBE (테이블명); 으로 확인 가능하다.
INSERT INTO 테이블명 VALUES(값1, 값2..etc);
-- 1-1 사용법
-- 컬럼값이 문자열 이거나 날짜 값일 경우 '' 또는 ""안에 입력 한다.
-- 예) A란 테이블에 Name컬럼, Date컬럼이 있다면
INSERT INTO A VALUES('2023-01-01', "Homi");
-- 1-2 사용법
-- AUTO_INCREMENT 속성이 붙은 컬럼의 테이블에 데이터를 추가 할 경우 NULL 값을 넣어준다.
-- MySQL은 처리 시 NULL(비어있는)값이기 때문에 AUTO_INCREMENT(자동으로 증가)를 수행 한다.
-- 예) B란 테이블에 Id라는 AUTO_INCREMENT 속성이 붙은 컬럼과 Number 컬럼이 있다면
INSERT INTO B VALUES(NULL, 1);
-- 1-3 사용법
-- 한번의 Insert문으로 여러개의 데이터를 동시에 추가 할 수 있다.
-- 예) A란 테이블에 Name컬럼, Date컬럼이 있고 사이먼 이라는 이름의 날짜가 2023-02-01인 사람과 도미닉 이라는 이름의 날짜가 2023-02-02인 사람을 한번에 추가 할 경우
INSERT INTO A VALUES('사이먼', '2023-02-01'), ('도미닉', '2023-02-02');
-- 2 기본 형식(특정 컬럼만 값을 입력할 경우)
-- 테이블 명 다음 (컬럼명1, 컬럼명2..)로 원하는 컬럼을 쓴다
INSERT INTO 테이블명(컬럼명1, 컬럼명2..etc) VALUES(값1, 값2..etc);
-- 1-2 사용법을 할 경우
INSERT INTO B(Number) VALUES(1);
-- 1-3 사용법을 할 경우
INSERT INTO A(Name) VALUES('사이먼'), ('도미닉');
-- 3 기본 형식(컬럼과 값을 묶어서 입력할 경우)
-- SET 키워드를 이용해 컬럼명과 컬럼값을 묶는다
INSERT INTO 테이블명 SET 컬럼명1=값1, 컬럼명2=값2..etc;
-- 1-2 사용법을 할 경우
INSERT INTO B SET Number = 1;
-- 1-3 사용법은 불가능하다.
다수의 데이터를 한 번에 Insert 할 경우 왼쪽에서 오른쪽 순으로 저장된다.
- 파일을 통해 데이터 추가하기 ★
-- 1 기본 형식
-- 파일 안에 Insert문들을 적은 다음 적용하는 방법
-- 예) insert_test.sql라는 파일을 만들고 파일 안에 INSERT INTO member(last_name, first_name) VALUES('Stein', 'Waldo');을 입력 한 다음 파일을 저장한다.
-- 1-1 사용법
-- 두가지 방법이 있다
-- 1-1-1 mysql을 실행 하지 않은 상태에서 적용 하는 방법
mysql 데이터베이스 명 < 경로명/insert_test.sql -p -u 사용자 명
-- 1-1-2 mysql을 실행한 상태에서 파일을 적용하는 방법
SOURCE 경로명/insert_test.sql;
-- 2 기본 형식
-- 데이터만 존재하는 파일을 적용하는 방법
-- LOAD DATA문을 사용해서 추가한다.
-- LOCAL를 사용할 경우 로컬 머신 내에서 파일을 찾고 아닐 경우 원격 머신에서 파일을 찾는다.
LOAD DATA LOCAL INFILE '경로명/파일명' INTO TABLE 테이블명;
-- 2-1 사용법
-- 예)data_test.txt라는 파일을 만들고 파일 안에 \N Lacke Bruce \N 2012-10-10 \N 617 West Lawn Av. Aberdeen SD 97919 171-132-0360 Vietnam War,Education를 입력 한 다음 엔터 키 입력 후 파일을 저장한다.
-- 예)데이터 저장 시 null 표시는 \n으로 표현하고 각 컬럼마다 'Tab'키로 구분하고 엔터키를 한개의 데이터들의 집합으로 인식한다
LOAD DATA LOCAL INFILE 'member_test.txt' INTO TABLE member;
-- 예)위 데이터 형식은 member라는 테이블을 만들고 테이블 형식에 맞춰 입력한 것인데 테이블 형식은 다음과 같다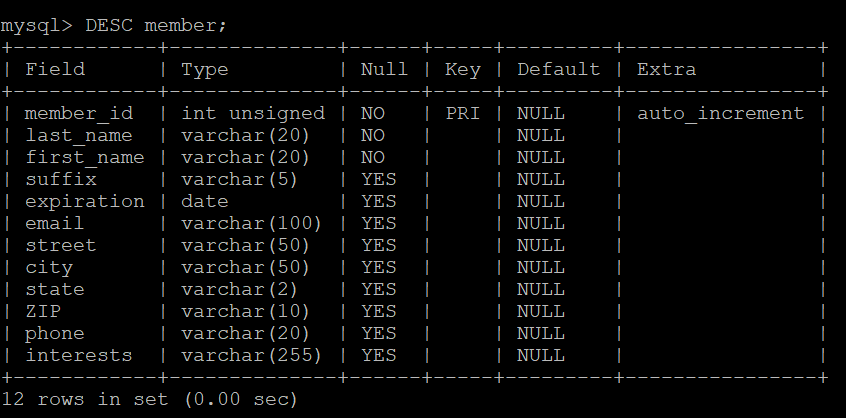
-- 3 기본 형식
-- 데이터만 존재하는 파일을 적용하는 방법
-- mysqlimport 클라이언트를 사용한다(mysql 설치시 같이 설치된다)
-- mysqlimport 가 실행 될 경우 내부적으로 LOAD DATA문을 실행한다
-- mysqlimport 는 처음 나오는 "."의 좌측을 테이블 명으로 인식한다, 그렇기 때문에 파일명이 테이블 명이 아닐 경우 에러가 난다.
mysqlimport --local -p -u 사용자명 데이터베이스명 경로명/파일명
-- 3-1 사용법
-- "." 좌측에 대한 예를 들자면 member 테이블이 있을 때 member1.txt, member2.txt 파일을 mysqlimport 클라이언트를 사용해서 실행 할 경우 에러가 난다.
mysqlimport --local sampdb member1.txt;
mysqlimport --local sampdb member2.txt;
-- 위와 같이 두번의 실행을 할 경우 파일명이 member1, member2이기 때문에 member1 테이블, member2테이블을 찾아서 추가 할려고 하기 때문에 에러가 난다.
-- 해결 방법은 여러 가지가 있겠지만 한가지 방법은
mysqlimport --local sampdb member.1.txt;
mysqlimport --local sampdb member.2.txt;
-- 이런 식으로 파일을 만들어서 실행 한다면 member테이블에 적용 된다.- 테이블 데이터 검색
- SELECT 문★
-- 1. 기본 형식
-- 기본적으로 SELECT, FROM, WHERE 한 쌍의 구문으로 사용
-- SELECT (컬럼1, 컬럼2..etc 또는 *) FROM 테이블명 WHERE 조건1, 조건2..etc
-- 1-1 사용법
-- president테이블에 모든 컬럼들의 값을 검색 할 경우
SELECT * FROM president;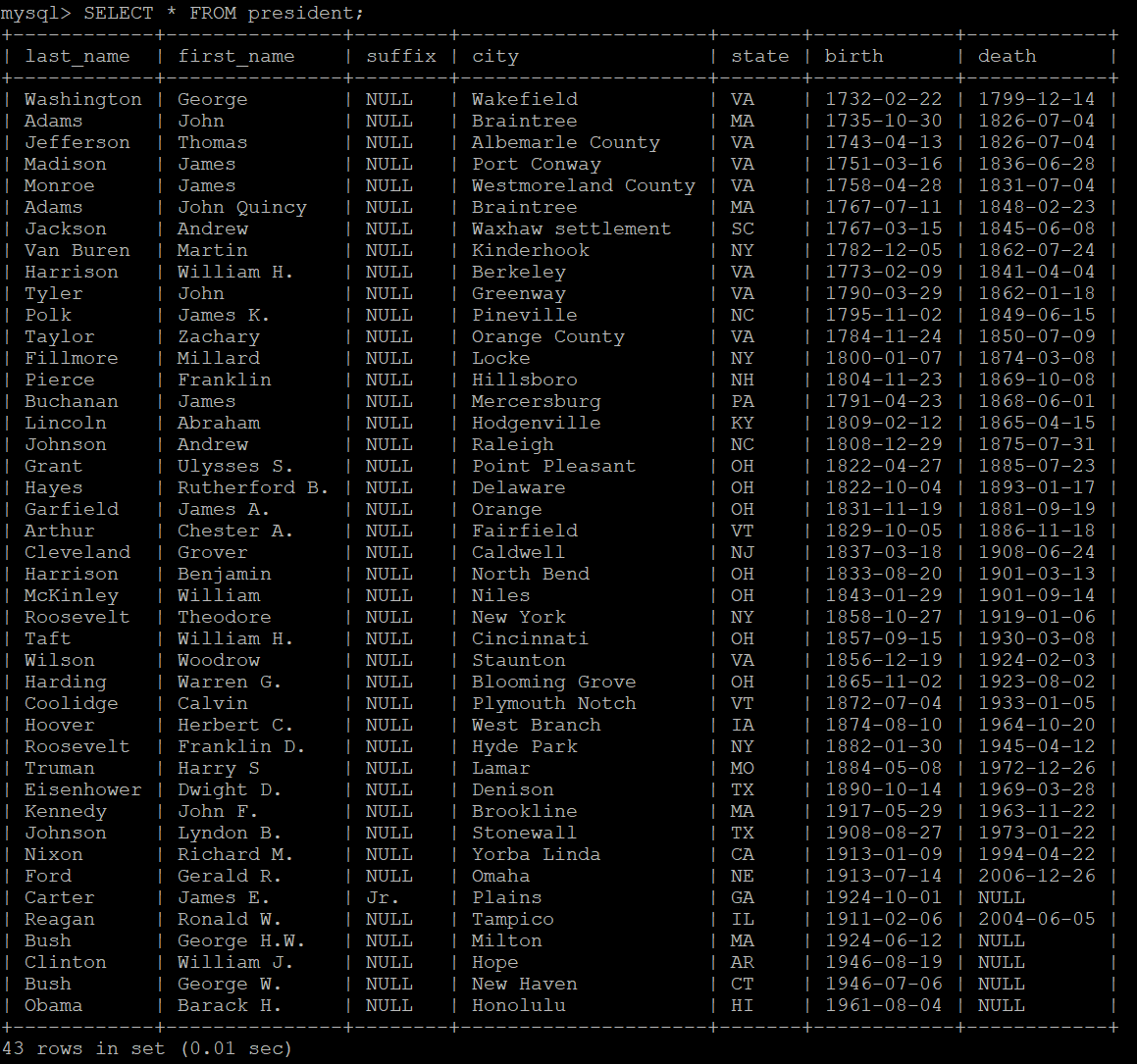
-- 2. 기본 형식
-- SELECT에 원하는 컬럼만 입력 후 검색
-- 컬럼 순서는 원하는데로 입력 가능
-- 2-1. 사용법
SELECT first_name, last_name FROM president;
-- 2-2. 사용법
SELECT last_name, first_name FROM president;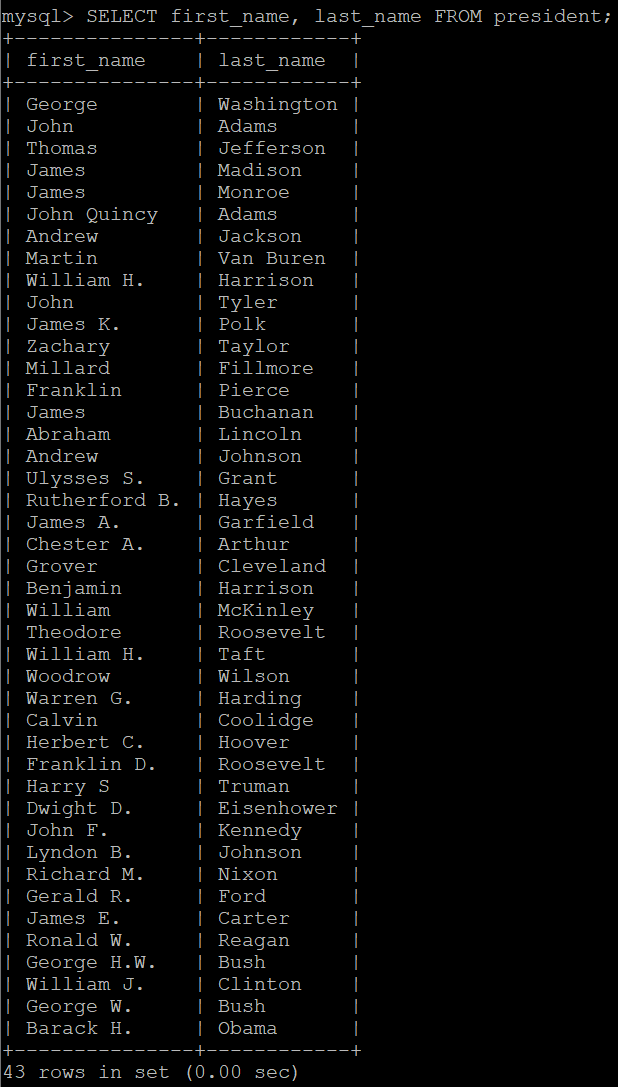
-- 3. 기본 형식
-- SELECT 에 특정 컬럼을 입력하고 WHERE 절에 조건을 입력해서 해당 조건에 맞는 컬럼값을 검색 할수 있음
-- 3-1. 사용법
SELECT birth FROM sampdb.president WHERE last_name = 'Eisenhower';
-- 4.기본 형식
-- FROM 절을 사용하지 않고 사용 가능
-- FROM 절을 통한 테이블 참조를 해서 값을 검색하는 경우가 아닐 경우 사용
-- 4-1. 사용법
SELECT 2+2, 'Hello, world', VERSION();
-- 주의 사항
-- 1. MySQL은 컬럼의 대소문자 구문을 하지 않는다.
-- 2. 하지만 데이터베이스명, 테이블명은 어느 OS에서 사용중인가에 따라 대소문자를 구별 할수도 있고 안할수도 있다.
-- 보통 윈도우에서는 대소문자는 구문하지 않는다.
-- 유닉스/리눅스 계열에서는 대소문자를 구문한다.
-- 이와 같은 차이점은 OS의 파일 시스템에서 기인한다.-- 5. 사용법
-- WHERE 절을 통해 조건 검사를 할 때 사용할 수 있는 연산자 종류
산술 연산자
| 연산자 | 의미 |
| + | 더하기 |
| - | 빼기 |
| * | 곱하기 |
| / | 나누기 |
| DIV | 정수형 나누기 |
| % | 나머지(Modulo) |
비교 연산자
| 연산자 | 의미 |
| < | 오른쪽보다 작은 |
| <= | 오른쪽보다 작거나 같은 |
| = | 오른쪽과 같은 |
| <=> | 오른쪽과 같은(NULL에도 쓸 수 있음) |
| <> 또는 != | 오른쪽과 같지 않은 |
| >= | 오른쪽보다 크거나 같은 |
| > | 오른쪽보다 큰 |
논리 연산자
| 연산자 | 의미 |
| AND | 논리 AND |
| OR | 논리 OR |
| XOR | 배타적 논리 OR |
| NOT | 논리 부정 |
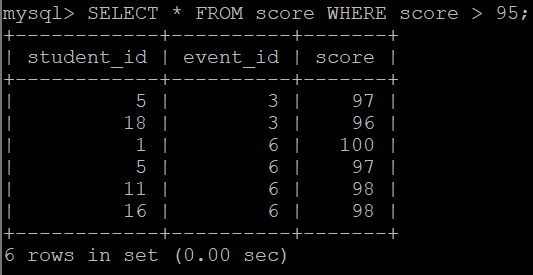
-- 5.1 사용법
-- 스코어 테이블에서 95점보다 큰 점수를 가지고 있는 학생들의 정보를 검색
SELECT * FROM score WHERE score > 95;
-- 5.2 사용법
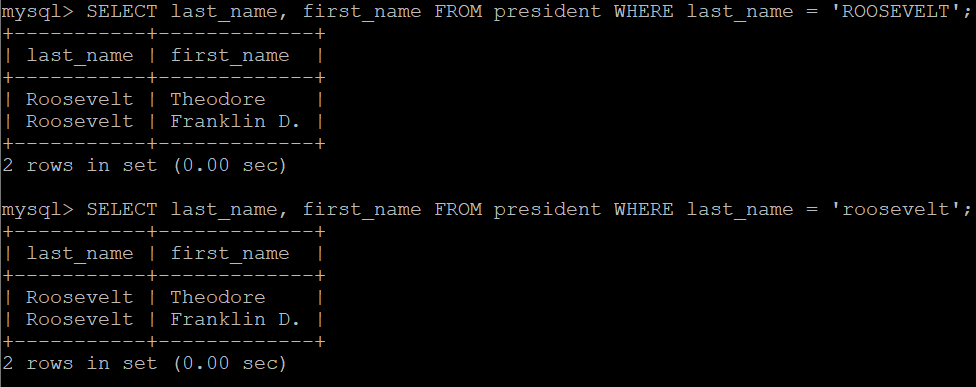
-- WHERE 조건에 칼럼 값 비교 시 값 자체는 대소문자 구문 없이 조건 검사함
SELECT last_name, first_name FROM president WHERE last_name = 'ROOSEVELT';
SELECT last_name, first_name FROM president WHERE last_name = 'roosevelt';
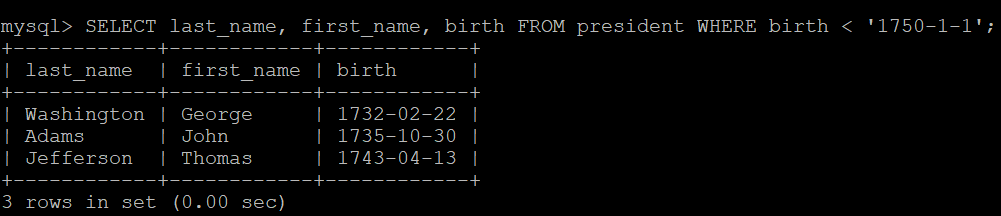
-- 5.3 사용법
-- 날짜 범위 조건 검사 가능
-- 1750년 1월 1일 이전 사람의 정보를 검색
SELECT last_name, first_name, birth FROM president WHERE birth < '1750-1-1';
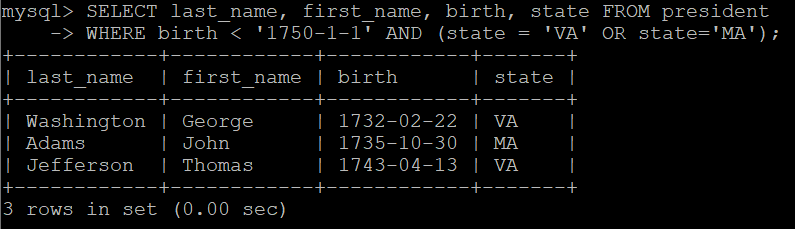
-- 5.4 사용법
-- 복합 조건 검색 가능
-- 대통령 테이블에서 생일이 1750-1-1일 이전 출생 중에 state 값이 VA 또는 MA인 값을 가지고 있는 대통령 검색
SELECT last_name, first_name, birth, state FROM president WHERE birth < '1750-1-1' AND (state = 'VA' OR state='MA');
-- 주의 사항
-- WHERE절을 사용 할때 논리적인 생각으로 조건을 검사한다 생각하지만 그렇지 않은 경우가 발생할수 있다.
-- 만약 대통령 테이블에서 버지니아와 메사추세츠에서 태어난 대통령들을 검색한다고 해보자
SELECT last_name, first_name, state FROM president WHERE state = 'VA' AND state='MA';
-- 위 화면과 같이 아무 값도 검색 할수 없다.
-- 이유는 위 쿼리를 해석 해보면 "버지니아와 메사추세츠 양쪽 모두에서 태어난 대통령들을 선택하라"는 뜻이기 때문이다.
-- 사람은 동시에 두 지역에서 태어날수 없다.
-- 일상 생활에서 사용 하는 "~과(AND)"를 쿼리식으로 표현 할때는 잘 생각해야 한다.
-- 위 쿼리의 경우 OR을 사용해야 한다.
SELECT last_name, first_name, state FROM president WHERE state = 'VA' OR state='MA';
-- 5.5 사용법
-- IN 연산자를 사용한다면 OR 연산자를 사용할때보다 쿼리가 더 간단 해진다.
SELECT last_name, first_name, state FROM president WHERE state IN('VA','MA');
-- 6. 기본 형식
-- SQL문법에서의 NULL의 의미는 "값이 없음"이란 의미 외에 "값을 알수 없음"이란 의미도 가짐
-- 만약 아래와 같은 검색을 할경우 결과가 어떻게 되는가?
SELECT NULL < 0, null = 0, NULL <> 0, NULL > 0;
-- 위와 같이 NULL값을 반환한다.
-- 이유는 모르는 값(NULL)에 비교 연산을 했기 때문에 몰르는 값을 반환 한거다
-- NULL값에 대한 검사가 필요 할 경우 IS NULL 또는 IS NOT NULL 키워드를 사용해서 검사한다.
-- 예외적으로 <=> 연산자도 사용 가능하다
-- IS NULL : NULL인것
-- <=> : 같은것(NULL값과도 비교 가능)
-- IS NOT NULL : NULL이 아닌것
-- 예)대통령 테이블에 살아있는 대통령 리스트를 반환하는 쿼리를 만들때 아래와 같은 식은 불가능하다.
SELECT last_name, first_name, death FROM president WHERE death = NULL;
-- IS NULL 키워드를 사용하기 때문에 가능하다.
SELECT last_name, first_name, death FROM president WHERE death IS NULL;
-- 7. 기본 형식
-- ORDER BY(정렬)문을 사용해서 데이터를 정렬할수 있음
-- SELECT * FROM (테이블명) ORDER BY (컬럼명) [ASC or DESC];
-- 기본적으로 오름차순(ASC)설정이 되어있어서 ASC 키워드는 붙이지 않아도 오름차순으로 출력
-- 내림차순으로 출력하고 싶을 경우 DESC 키워드 입력
-- 7.1 사용법
-- NULL을 가지고 있는 데이터의 정렬방법
-- 예) 생존하는 사람들을 출력 한다음 죽은 사람들을 출력
SELECT last_name, first_name, death FROM sampdb.president ORDER BY IF(death IS NULL, 0, 1);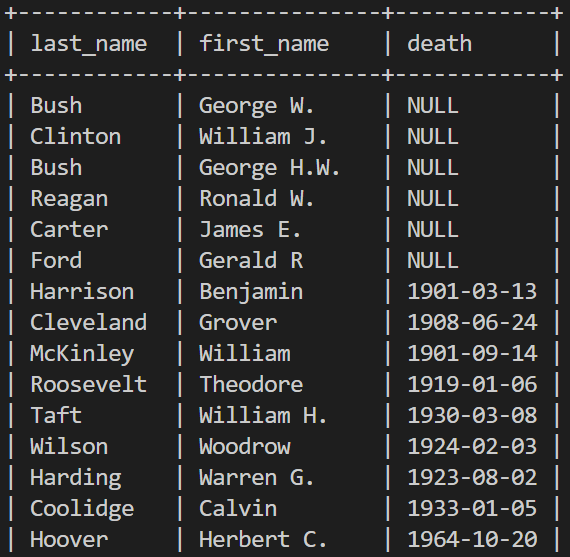
-- 7.2 사용법
-- 여러 컬럼을 정렬하고 싶을 경우 ORDER BY (컬럼명1), (컬럼명2)..로 정렬시킨다
-- 예) 태어난 주는 내림차순(DESC)순으로 정렬 한다음 각 주안에서 last_name은 오름차순(ASC)로 정렬
-- 8.기본형식
-- 특정 개수만큼 보고 싶을 경우 LIMIT 키워드 사용
SELECT * FROM (테이블명) LIMIT (보고싶은개수);
-- 보통 ORDER BY 절과 가치 사용한다
SELECT * FROM (테이블명) ORDER BY (컬럼명) LIMIT (보고싶은 개수);
-- 생일이 빠른 순으로 5명을 출력
SELECT last_name, first_name, birth FROM president ORDER BY birth LIMIT 5;
-- 8.1 사용법
-- 특정 행을 건너 뛴 다음 원하는 개수만큼 출력하는 기능도 가능하다
-- 예)생일이 빠른 순서 중 처음 10명은 제외하고 5명 출력
SELECT last_name, first_name, birth FROM president ORDER BY birth LIMIT 10, 5;
-- 8.2사용법
-- RAND()함수를 사용하면 랜덤으로 LIMIT(원하는 개수)만큼 출력이 가능하다
-- 예) 랜덤으로 데이터 안에서 3명 출력
SELECT last_name, first_name, birth FROM president ORDER BY RAND() LIMIT 3;
9. 기본형식
-- 계산식으로 결과를 출력할수 있음
SELECT 17, FORMAT (SQRT (25+13), 3);
9.1 사용법
-- 표현식을 사용해 DB에 있는 컬럼들을 연결지어 출력
-- 예) 대통령 테이블에 이름정보를 띄어쓰기로 연결하고 도시정보를 쉼표로 연결지어서 출력
SELECT CONCAT(first_name, ' ', last_name), CONCAT(city, ', ', state) FROM president LIMIT 5;
9.2 사용법
-- 컬럼명은 검색할때의 네이밍이 되기 때문에 좀더 명확하게 보기 위해 AS 키워드 사용
mysql> SELECT CONCAT(first_name, ' ', last_name) AS Name, CONCAT(city, ', ', state) AS Birthplace
-> FROM president LIMIT 5;
-- AS 키워드로 컬럼명 변경 시 띄어쓰기된 컬럼명을 사용하고 싶을경우 ''안에 입력
mysql> SELECT CONCAT(first_name, ' ', last_name) AS 'President Name', CONCAT(city, ', ', state) AS 'Place of Birth'
-> FROM president LIMIT 5;

9.3 사용법
-- AS 키워드는 as 없이도 사용 가능하다
SELECT 1, 2 AS two, 3 three;
--위와 같은 이유때문에 콤마를 안할 경우 원하는 값이 안나올수 있다.
--예) 대통령의 풀 네임을 출력하고 싶은데 콤마가 없어서 퍼스트 네임만 나오는 쿼리
SELECT first_name last_name FROM president LIMIT 5;

10. 기본형식
-- 날짜 계산
-- 테스트해볼 날짜 타입은 DATE형 타입
-- 실제 라이브에서는 DATETIME형을 사용하거나 TIMESTAMP형을 사용하기 때문에 쿼리를 보고 응용이 필요하다
-- 나중에 글 정리시 위 타입에 대해서도 기입할 예정
-- 2002-10-01날짜의 데이터를 가져오는 쿼리
SELECT * FROM event WHERE date = '2002-10-01';
10.1 사용법
-- 1970-01-01 ~ 1980-01-01 사이에 죽은 사람의 정보를 가져오는 쿼리
mysql> SELECT last_name, first_name, death FROM president
-> WHERE death >= '1970-01-01' AND death < '1980-01-01';
10.2 사용법
-- 3월에 태어난 사람들을 검색하는 쿼리
SELECT last_name, first_name, birth FROM president WHERE MONTH(birth) = 3
-- 위와 같지만 월을 이름으로 검색하는 쿼리
SELECT last_name, first_name, birth FROM president WHERE MONTHNAME(birth) = 'March';

10.3 사용법
-- 월, 일이 같은 데이터를 검색하는 쿼리
mysql> SELECT last_name, first_name, birth FROM president
-> WHERE MONTH(birth) = 3 AND DAYOFMONTH(birth) = 29;
10.4 사용법
-- 현재 날짜를 기준으로 쿼리수정없이 데이터를 가져오는 쿼리
SELECT last_name, first_name, birth FROM president WHERE MONTH(birth) = MONTH(CURDATE()) AND DAYOFMONTH(birth) = DAYOFMONTH(CURDATE());
10.5 사용법
-- 시간의 차를 구하는 쿼리
-- 예) 가장 오랫동안 생존한 데이터를 구하는 쿼리
mysql> SELECT last_name, first_name, birth, death, TIMESTAMPDIFF(YEAR, birth, death) AS age
-> FROM president
-> WHERE death IS NOT NULL
-> ORDER BY age DESC
-> LIMIT 5;
10.6 사용법
-- 오늘 날짜를 기준으로 회원 만기일이 60일 남은 유저를 검색하는 쿼리
mysql> SELECT last_name, first_name, expiration
-> FROM member
-> WHERE (TO_DAYS(expiration) - TO_DAYS(CURDATE())) < 60
-> LIMIT 5;
-- 위 쿼리는 TIMESTAMPDIFF 함수로도 만들어 낼수있다
mysql> SELECT last_name, first_name, expiration
-> FROM member
-> WHERE TIMESTAMPDIFF(DAY, CURDATE(), expiration ) < 60
-> LIMIT 5;

10.7 사용법
-- 날짜증가 함수(DATE_ADD)
-- 예)1970-01-01 부터 10년뒤 날짜 쿼리
SELECT DATE_ADD('1970-1-1', INTERVAL 10 YEAR);
-- 날짜감소 함수(DATE_SUB)
-- 예)1970-01-01 부터 10년전 날짜 쿼리
SELECT DATE_SUB('1970-1-1', INTERVAL 10 YEAR);

10.8 사용법
-- 1970년 1월 1일부터 1980년 1월 1일 사이 죽은 대통령을 구하는 쿼리
mysql> SELECT last_name, first_name, death
-> FROM president
-> WHERE death >= '1970-01-01'
-> AND
-> death < DATE_ADD('1970-01-01', INTERVAL 10 YEAR);
10.9 사용법
-- 현재시간을 기준으로 회원 자격증이 60일 이내로 갱신해야 되는 회원들을 검색 쿼리
mysql> SELECT last_name, first_name, expiration
-> FROM member
-> WHERE expiration < DATE_ADD(CURDATE(), INTERVAL 60 DAY)
-> LIMIT 5;
10.10 사용법
-- 현재날짜를 기준으로 60일동안 치과검진을 받지 않은 유저 검색 쿼리
mysql> SELECT last_name, first_name, last_visit
-> FROM patient
-> WHERE last_visit < DATE_SUB(CURDATE(), INTERVAL 60 DAY)
-> LIMIT 5;11. 기본형식
-- 패턴
-- 값 중 부분이 일치하는 값들을 가져오기 위한 방법
-- 명령어 LIKE 또는 NOT LIKE 를 이용하며 와일드카드를 사용해서 검사
-- '%' 와일드 카드
-- 아무 문자나 대응되는 시퀀스
-- last_name 데이터가 소문자 'w' 혹은 대문자 'W' 로 시작하는 데이터를 가져오는 쿼리
SELECT last_name, first_name FROM president WHERE last_name LIKE 'W%';
-- last_name 데이터가 소문자 'w' 혹은 대문자 'W' 를 가지는 데이터를 가져오는 쿼리
SELECT last_name, first_name FROM president WHERE last_name LIKE '%W%';
11.1 사용법
-- '_' 와일드카드
-- 문자 개수에 대응
-- 4개의 문자를 포함하는 쿼리
SELECT last_name, first_name FROM president WHERE last_name LIKE '____';
12. 기본형식
-- Join
-- 복수의 테이블에서 정보를 검색할때 사용
-- Sub Query
-- SELECT문 안에 중첩된 SELECT문을 사용12-1. 사용법
-- Join
-- 예) 퀴즈와 시험을 했었던 정보를 관리하는 event 테이블이 있다
-- 컬럼
-- date : 시작한 날
-- type : 퀴즈(Q) 또는 시험(T)
-- event_id : 이벤트 아이디
-- 이벤트에서 학생들의 점수를 관리하는 score 테이블이 있다
-- 컬럼
-- student_id : 학생 아이디
-- event_id : 이벤트 아이디
-- score : 점수

-- 주어진 날짜를 기준으로 퀴즈 점수 혹은 시험 점수를 가져오는 쿼리
SELECT student_id, date, score, type
-> FROM event INNER JOIN score
-> ON event.event_id = score.event_id
-> WHERE date = '2002-09-23';
-- 위 쿼리를 분석하면 몇가지 내용을 알수 있다.
-- (1). On 절에서 tbl_name.col_name문법을 사용해서 결합 시킨다.
-- 이유는 서로 다른 두 테이블에서 같은 컬럼명을 연결 시킬 때 테이블 수식어를 사용하지 않으면
-- 어떤 테이블의 컬럼명인지 모호해 지기 때문에 명확하게 하기 위해서 사용한다
-- 반대로 SELECT 절에 컬럼명만 사용해서 쿼리했는데 이게 가능한 이유는 두 테이블에 같은 이름의
-- 컬럼명이 없기 때문에 가능했던 거고 만약 같은 컬럼명이 있다면 테이블 수식어를 써야한다
-- 위의 쿼리에서 student 테이블을 참고하여 학생 이름도 가치 출력하는 쿼리
SELECT student.name, student.student_id, event.date, score.score, event.type
-> FROM event INNER JOIN score INNER JOIN student
-> ON event.event_id = score.event_id
-> AND student.student_id = score.student_id
-> WHERE event.date = '2002-09-23';
-- 학생들의 결석 통계를 내는 쿼리
SELECT student.student_id, student.name,
-> COUNT(absence.date) AS absences
-> FROM student INNER JOIN absence
-> ON student.student_id = absence.student_id
-> GROUP BY student.student_id;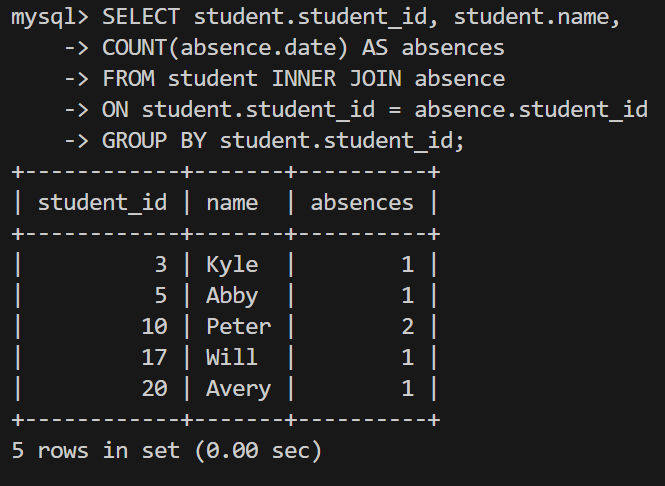
-- 위 쿼리에서 궁금증이 하나 일어났다
-- 만약 GROUP BY 절을 생략하고 사용하면 어떻게 될까?
-- 테스트 해보자
SELECT student.student_id, student.name, COUNT(absence.date) AS absences
FROM student INNER JOIN absence ON student.student_id = absence.student_id;
-- 에러 내용을 보면 집계 함수를 사용할 경우 GROUP BY 절을 사용해야 된다는 에러 메세지다
-- 그렇다면 위 쿼리에서 집계 함수는 뭘까?
-- COUNT()함수가 집계 함수다
-- 그렇다면 COUNT()함수를 사용하지 않고 사용한다면 어떻게 될까?
SELECT student.student_id, student.name, absence.date AS absences
FROM student INNER JOIN absence ON student.student_id = absence.student_id;
-- 정상적으로 출력된다.
-- 대신 COUNT()함수를 사용하지 않았기 때문에 모든 데이터가 출력됨을 볼수 있다.
-- 잊지말자. (집계)통계 함수 사용 시 GROUP BY 절을 꼭 사용하자!통계 참고 : https://aaaag.tistory.com/77
MySQL 통계 모음
이 글은 MySQL 명령어 모음에 쓸려다가 내용이 길고 중요한 내용이라 새로 포스트를 만들어 적는다. 참고 https://aaaag.tistory.com/50 MySQL 명령어 모음 히스토리 테이블 내용 출력 부분에 부분 칼럼명으
aaaag.tistory.com
-- 위에서 결석 통계를 출력하는 쿼리를 만들었었다
SELECT student.student_id, student.name,
-> COUNT(absence.date) AS absences
-> FROM student INNER JOIN absence
-> ON student.student_id = absence.student_id
-> GROUP BY student.student_id;
-- 만약 쿼리 요청자가 결석한 학생들을 출력하는 쿼리뿐만 아니라 결석하지 않은 학생들의 정보도
-- 가치 요청한다면 처음의 요청한 쿼리와 다른 질문이 되기 때문에 다른 쿼리를 만들어야 한다.
-- 이럴때 사용할수 있는 쿼리가 Left Join이다
-- Left Join은 Join 관계에서 처음 적은 테이블을 기준으로 모든 행을 만들고 오른쪽에 적은 테이블을 결합 시키는 절이다.
SELECT student.student_id, student.name,
-> COUNT(absence.date) AS absences
-> FROM student LEFT JOIN absence
-> ON student.student_id = absence.student_id
-> GROUP BY student.student_id;
-- 통계 함수를 사용해서 Join을 하는 경우를 다시 확인하자
-- score테이블에 통계 함수들을 사용해서 출력 시 event 테이블의 type 컬럼이나 date 컬럼들을 가치 출력하는 쿼리
SELECT
-> event.date, event.type,
-> MIN(score.score) AS minimum,
-> MAX(score.score) AS maximum,
-> MAX(score.score) - MIN(score.score) + 1 AS span,
-> SUM(score.score) AS total,
-> AVG(score.score) AS average,
-> COUNT(score.score) AS count
-> FROM score INNER JOIN event
-> ON score.event_id = event.event_id
-> GROUP BY event.date, event.type;
-- event 날짜와 학생들의 성별대로 시험을 본 인원수와 평균점수를 구하는 쿼리
SELECT event.date, student.sex,
-> COUNT(score.score) AS count, AVG(score.score) AS average
-> FROM event INNER JOIN score INNER JOIN student
-> ON event.event_id = score.event_id
-> AND score.student_id = student.student_id
-> GROUP BY event.date, student.sex;
-- 이제까지 시험을 본 학생들의 총점과 시험을 치룬 횟수를 구하는 쿼리
SELECT student.student_id, student.name,
-> SUM(score.score) AS total, COUNT(score.score) AS n
-> FROM event INNER JOIN score INNER JOIN student
-> ON event.event_id = score.event_id
-> AND score.student_id = student.student_id
-> GROUP BY score.student_id
-> ORDER BY total;
-- 때론, 같은 테이블을 결합해서 원하는 결과를 출력해야 될 때가 있다
-- 예) 대통령 테이블에서 같은 도시에 태어난 대통령들을 구하는 쿼리
SELECT p1.last_name, p1.first_name, p1.city, p1.state
-> FROM president AS p1 INNER JOIN president AS p2
-> ON p1.city = p2.city AND p1.state = p2.state
-> WHERE (p1.last_name <> p2.last_name OR p1.first_name <> p2.first_name)
-> ORDER BY state, city, last_name;
-- 에일리어스 P1, P2를 만든 후 SELECT 문에서 어떤 컬럼인지 모호해서 에러가 나는걸 방지하기 위해 P1을 사용했다
-- 주의할 점은 자기 자신이 출력되는걸 방지하기 위해 WHERE 절로 제외하는 문을 적었다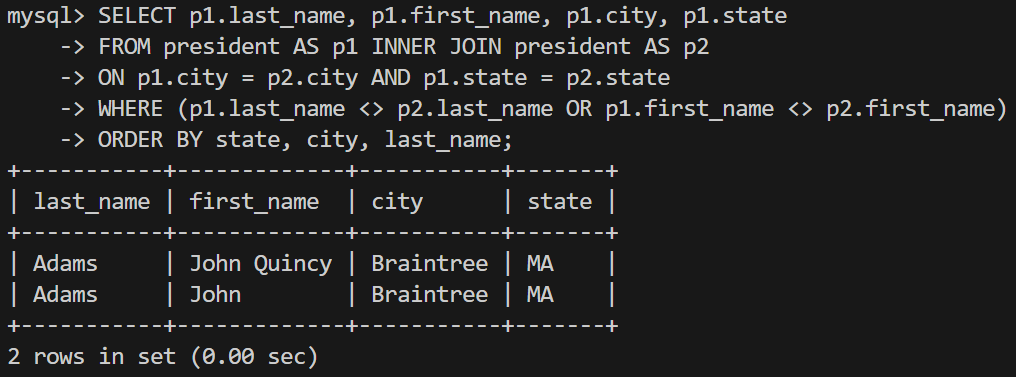
-- 위와 비슷한 예로 생일이 같은 대통령을 찾는 쿼리를 만든다면 위와 동일하게 할순 없다
-- 이유는 출생 연월일을 직접 비교할 경우 다른 해에 태어난 대통령일 경우 비교가 실패되기 때문이다
-- 이럴땐 MONTH(), DAYOFMONTH()를 사용하여 년도를 제외한 달과 날짜를 비교한다
SELECT p1.last_name, p1.first_name, p1.birth
-> FROM president AS p1 INNER JOIN president AS p2
-> WHERE MONTH(p1.birth) = MONTH(p2.birth)
-> AND DAYOFMONTH(p1.birth) = DAYOFMONTH(p2.birth)
-> AND (p1.last_name <> p2.last_name OR p1.first_name <> p2.first_name)
-> ORDER BY p1.last_name;
-- DAYOFYEAR()함수를 사용할 경우 윤년인 해의 날짜와 그렇지 않은 해의 날짜를 비교하게 되면 결과가 잘못될수 있다
-- 중첩된 SELECT 문
-- 예) 결석하지 않은 학생들을 찾는 쿼리(absence 테이블은 결석 테이블)
SELECT * FROM student
-> WHERE student_id NOT IN (SELECT student_id FROM absence);
-- 예) Jackson(last_name), Andrew(first_name)인 대통령보다 먼저 태어난 대통령들을 구하는 쿼리
SELECT last_name, first_name, birth FROM president
WHERE birth < (SELECT birth FROM president WHERE last_name = 'Jackson' AND first_name = 'Andrew');
13. 기본형식
-- 쿼리에 사용자 정의 변수를 설정하고 사용하는 방법
-- @var_name := value 형식의 표현식 사용
-- 예)Andrew Jackson 보다 빠른 나이의 대통령들을 가져오는 쿼리
SELECT @birth := birth FROM president WHERE last_name = 'Jackson' AND first_name = 'Andrew';
SELECT last_name, first_name, birth FROM president WHERE birth < @birth ORDER BY birth;
-- 위 쿼리를 보면 Andrew Jackson의 생년월일을 변수로 저장 후 다음 쿼리에서 사용한다.
-- Join 또는 서브쿼리로 한문장으로 만들수 있는데 상황에 따라 원하는 문법으로 사용하면 좋을거 같다
13-1. 사용법
-- SET문을 사용해서 변수에 값을 대입할수 있다.
-- 예)today, oneWeekAgo를 가져오는 쿼리
SET @today = CURDATE();
set @one_week_ago := DATE_SUB(@today, INTERVAL 7 DAY);
SELECT @today, @one_week_ago;
delete 문
- 테이블의 행을 삭제하는 쿼리
- where을 붙일 경우 조건식이 부합되는 결과만 삭제
-- 기본형식
DELETE FROM (TABLE_NAME); -- 전체 데이터삭제
DELETE FROM (TABLE_NAME) WHERE (조건1 = 값) -- 조건에 맞는 값들에 대한 데이터들 삭제-- tip
-- DELETE 문을 사용해서 확실하게 원하는 데이터들만 지우는지 확신이 서지 않은다면 SELETE문으로 선 확인 하자
-- 예) 오하이오 주에 태어난 대통령을 삭제한다면 먼저 검색쿼리를 만든다
SELECT * FROM president WHERE state = 'OH';
-- 정상적으로 데이터를 가져온다면 삭제쿼리로 변경한다
DELETE FROM president WHERE state = 'OH';
-- 데이터 삭제는 매우 위험한 쿼리 임으로 위와 같은 방식이 좋다 생각한다update 문
- 테이블의 데이터를 변경하는 쿼리
-- 기본형식
UPDATE (TABLE_NAME) SET CUL1 = VAL1 -- 전체 행 수정
UPDATE (TABLE_NAME) SET CUL1 = VAL1 WHERE 조건 = 값 -- 조건에 맞는 값들에 대한 데이터들 수정
-- 업데이트는 잘못 사용할 경우 매우 좁은 범위를 수정하거나 매우 넓은 범위의 데이터들을 수정하게 된다.
-- 업데이트 치기전에 셀렉트 문으로 검사 후 업데이트를 실행하는 습관을 들이는게 좋다