MySQL 통계 모음
2023. 6. 12. 22:56ㆍ카테고리 없음
728x90
이 글은 MySQL 명령어 모음에 쓸려다가 내용이 길고 중요한 내용이라 새로 포스트를 만들어 적는다.
참고
MySQL 명령어 모음
히스토리 테이블 내용 출력 부분에 부분 칼럼명으로 검색하는 방법 추가 명령어 컬러 강조 추가, 자주 사용하는 명령어 별 표시 강조 추가 SELECT문 추가 중 굉장히 장기적으로(예상 기간 올해 12
aaaag.tistory.com
1. 사용법
-- DISTINCT 명령어(중복된 값 제거)
-- 예) 대통령을 배출한 미국의 주들을 중복되지 않게 나열하는 쿼리
SELECT DISTINCT state FROM president ORDER BY state;
2. 사용법
-- COUNT 명령어(행의 개수를 반환)
-- 예) 멤버 테이블에 있는 데이터의 개수를 리턴하는 쿼리
SELECT COUNT(*) FROM member;
-- COUNT 명령어에 WHERE 명령어도 포함되어 실행 될 경우 해당 절의 행들의 개수를 반환
-- 예) 이벤트 테이블에서 얼마나 많은 이벤트를 했는지 리턴하는 쿼리
SELECT COUNT(*) FROM event WHERE type = 'Q';

-- COUNT(*)는 모든 행의 개수를 가져오고 COUNT(컬럼명)은 해당 컬럼값중 NULL이 아닌 개수를 가져온다
-- 예) 회원들 전체 인원수와 E-MAIL을 등록한 회원들의 인원수와 평생회원권을 등록한 회원의 인원수와 아닌 인원수를 가져오는 쿼리
SELECT COUNT(*), COUNT(email), COUNT(expiration) FROM member;
-- 전체 인원수 : 103
-- 이메일을 등록한 인원수 : 80
-- 만료일이 등록된 인원수 : 97
-- 평생회원권을 등록한 인원수(만료일이 없다면 평생회원권 등록 회원) : 103 - 97 = 6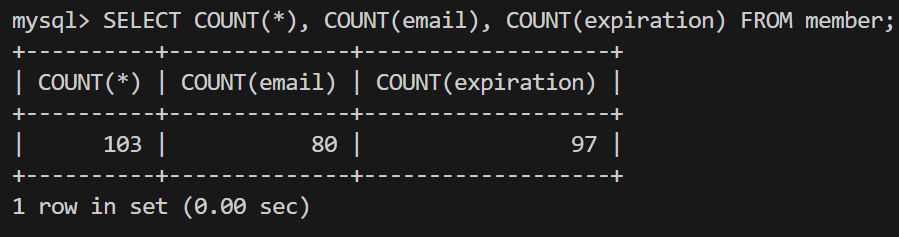
-- COUNT 함수와 DISTINCT 명령어를 가치 사용 할 경우 NULL이 아닌 값들의 수를 알수 있다.
-- 예) 각 주에 태어난 대통령의 수를 겹치지 않고 가져오는 쿼리.
-- 예) 만약 VA 주에서 3명이 태어났다면 해당 쿼리는 중복을 제외하고 1명만 반환
SELECT COUNT(DISTINCT state) FROM president;
3. 사용법
-- GROUP BY (컬럼을 그룹마다 묶어서 특정 값 얻기 위해 사용)
-- 예) 만약 학생 테이블에 학생들의 수를 가져오는 쿼리가 있다면
SELECT COUNT(*) FROM student;
-- 학생들 중 남자 학생들의 수와 여자학생들의 수를 알고 싶다면
SELECT COUNT(*) FROM student WHERE sex = 'm';
SELECT COUNT(*) FROM student WHERE sex = 'f';
-- 위와 같은 방법으로 쿼리를 여러번 사용해서 가져와야 된다
-- 하지만 위와 같은 방법은 좋은 방식은 아니다
-- 왜냐면 위와 같은 방법이 되는 테이블 구조도 있겠지만 안되는 테이블 구조에서는 다른 방법을 사용해야 한다
-- 그리고 위와 같은 방법은 쿼리를 여러번 호출하는데 만약 쿼리수가 많다면 이것도 만만치 않은 작업이다
-- 예를 들어 대통령 테이블에서 각 주마다 탄생한 대통령의 수를 가져오는 쿼리를 만들려면
-- 먼저 대통령이 태어난 각 주를 먼저 알아야 하고
SELECT DISTINCT state FROM president;
-- 각 주마다 몇명인지 알아야 하는 쿼리를 만들어야 한다
SELECT COUNT(*) FROM president WHERE state = 'VA';
SELECT COUNT(*) FROM president WHERE state = 'MA';
...etc
-- 위와 같은 상황을 해결하기 위해 GROUP BY 절로 변경하면 쉬워진다
-- 학생 테이블에 남자인원수와 여자인원수를 가져오는 쿼리
SELECT sex, COUNT(*) FROM student GROUP BY sex;
-- 각 주마다 태어난 대통령의 수를 가져오는 쿼리
SELECT state, COUNT(*) FROM president GROUP BY state;
-- 위 방식으로 인해 3가지 장점이 발생했다
-- (1). 각 컬럼값이 뭐가 들어있든 상관없이 사용 가능
-- (2). 하나의 쿼리로 해결
-- (3). 하나의 쿼리를 사용함으로써 출력 시 정렬가능
-- 예) 각 주마다 태어난 대통령의 수 중에 많이 배출한 주 부터 가져오는 쿼리
SELECT state, COUNT(*) AS count FROM president GROUP BY state ORDER BY count DESC;
-- 계산된 컬럼을 GROUP BY 절로 묶어서 보고 싶은 경우
-- 예) 대통령 테이블에서 각 달 마다 태어난 대통령의 수를 보는 쿼리
SELECT MONTH(birth) AS month, MONTHNAME(birth) AS monthName, COUNT(*) AS count FROM president GROUP BY monthName
ORDER BY month ASC;
-- !!위 쿼리를 실행하면 에러가 발생한다.
ERROR 1055 (42000): Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'sampdb.president.birth' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
-- 해석하면 현재 모등에서 sql_mode=only_full_group_by 세팅이 되있어서 실행이 안되다는 에러다
-- 해결 방법은 여러가지지만 현재는 테스트를 위해 임시로 모드를 해제하고 진행했다.
-- 재대로 해결하기 위해서 SUB QUERY 또는 그외 다른 방법등으로 해결해야 한다.
-- 예) 대통령 테이블에서 가장 많이 배출된 4개의 주를 순서대로 출력하는 쿼리
SELECT state, COUNT(*) AS count FROM president GROUP BY state ORDER BY count DESC LIMIT 4;
-- 예) 한 주에 2명 이상의 대통령을 배출한 주를 출력하는 쿼리
SELECT state, COUNT(*) AS count FROM president GROUP BY state HAVING count > 1 ORDER BY count DESC;
4. 사용법
-- 그외 통계 함수들
-- 예) 이벤트 테이블에서 최소값, 최대값, 총합, 평균값등 출력하는 쿼리
mysql> SELECT
-> event_id,
-> MIN(score) AS minimum,
-> MAX(score) AS maximum,
-> MAX(score) - MIN(score) + 1 AS span,
-> SUM(score) AS total,
-> AVG(score) AS average,
-> COUNT(score) AS count
-> FROM score
-> GROUP BY event_id;
-- 한줄
SELECT event_id, MIN(score) AS minimum, MAX(score) AS maximum, MAX(score) - MIN(score) + 1 AS span, SUM(score) AS total, AVG(score) AS average, COUNT(score) AS count FROM score GROUP BY event_id;
-- 위 쿼리는 event 테이블의 값이 퀴즈인지 시험인지에 따른 값의 정보가 아니라 두개를 합한 값이다
-- 퀴즈 정보의 통계 또는 시험 정보의 통계를 원한다면 테이블 조인도 사용하여 검사해야 한다
5. 사용법
-- WITH ROLLUP (통계를 요약해서 출력하는 기능)
-- 예) 학생 테이블에서 남자 수, 여자 수, 총 학생 수를 출력하는 쿼리
SELECT sex, COUNT(*) FROM student GROUP BY sex WITH ROLLUP;
-- 그외 통계 함수와 가치 사용 가능하다
-- 예) 이벤트 테이블에서 최소값, 최대값, 총합, 평균값등 출력 후 마지막에 요약정보를 출력하는 쿼리
mysql> SELECT
-> event_id,
-> MIN(score) AS minimum,
-> MAX(score) AS maximum,
-> MAX(score) - MIN(score) + 1 AS span,
-> SUM(score) AS total,
-> AVG(score) AS average,
-> COUNT(score) AS count
-> FROM score
-> GROUP BY event_id
-> WITH ROLLUP;
-- 한줄
SELECT event_id, MIN(score) AS minimum, MAX(score) AS maximum, MAX(score) - MIN(score) + 1 AS span, SUM(score) AS total, AVG(score) AS average, COUNT(score) AS count FROM score GROUP BY event_id WITH ROLLUP;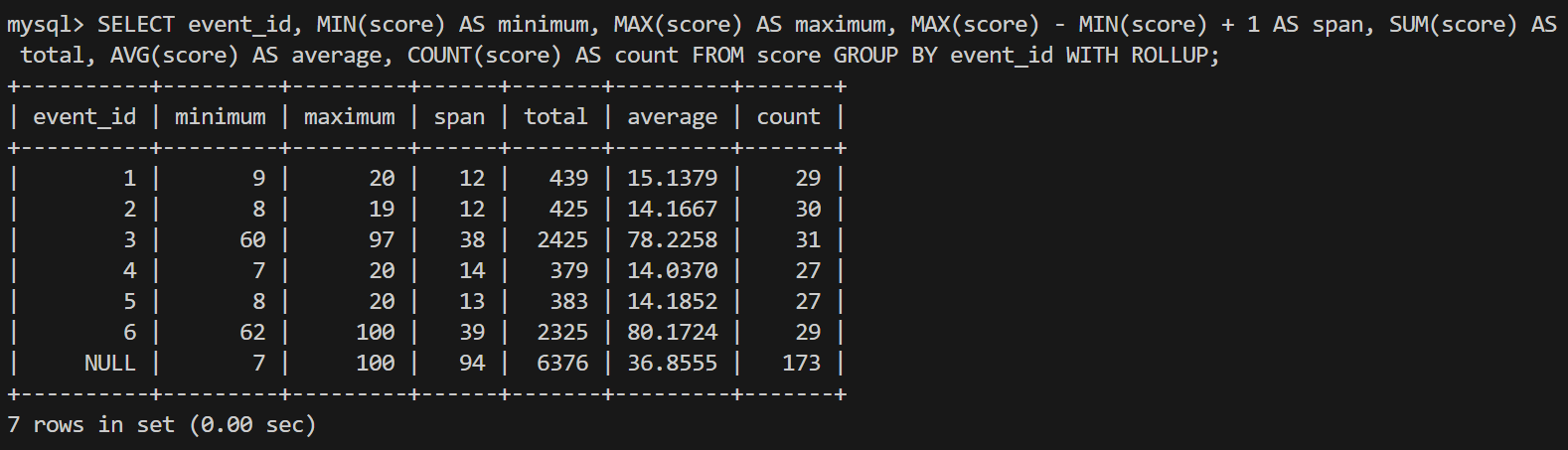
위와 같은 쿼리를 사용해서 통계를 계산한다.
조인 관련해서는 이 글 후반에 다시 쓸 거지만.. 중간에 이 글을 쓴 거는 Paul DuBois의 마지막 말 때문이다.
"통계 함수들은 강력하기에 그만큼 재밌고 많은 결과물을 만들어 낼수 있지만 금방 질린다"
이 말이 무슨 뜻 일까?
아래 예를 확인하자
--예) 태어난 주를 기준으로
-- 사망한 대통령들을 그룹으로 만든다음
-- 사망 당시의 나이를 계산해서
-- 평균 나이를 구한다음
-- 평균나이 기준으로 정렬하는 쿼리
mysql> SELECT state AS state,
-> AVG(TIMESTAMPDIFF(YEAR, birth, death)) AS age
-> FROM president
-> WHERE death IS NOT NULL
-> GROUP BY state
-> ORDER BY age;
-- 결국 위의 말은 생존하지 않은 대통령들에 대해서 출신 주를 기준으로 사망 당시의 평균 연령을 구하는 쿼리이다쿼리를 만들 순 있지만 만들어진 쿼리에 의미가 얼마나 존재할까?
앞으로 회사 생활을 하면서 쿼리를 만들 때 이런 의미 없는 쿼리들은 요청이 들어올 수 있다.
주로 경영 쪽 관련된 부서에서 오겠지.. 이런 쿼리를 반복해서 만든다면 결국 쉽게 질린다.